

こんなポーズの絵を生成したいんだけど、できるかな…?

OpenPoseでうまくいくかも!
Stable Diffusionで絵を生成するとき、思い通りのポーズにするのはかなり難しいですよね。
ポーズに関するプロンプトを使ってイメージに近づけることはできますが、プロンプトだけで指定するのが難しいポーズもあります。
そんなときに役立つのがOpenPoseです。こんな棒人間を見たことはありませんか?
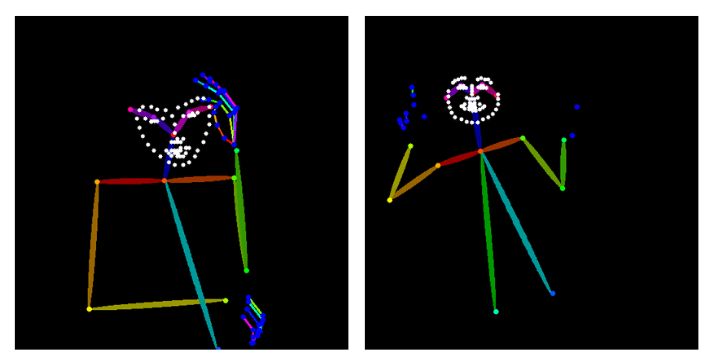
OpenPoseを使うと、プロンプトだけでは表現が難しいポーズもかなり正確に再現できます。
この記事では、そんなOpenPoseの導入方法と使い方について解説します。
- ポーズをできるだけ正確に再現したい
- 「棒人間」や「OpenPose」はなんとなく知っているけど、詳しい使い方を知りたい
OpenPoseとは
OpenPoseは、画像に写っている人間の姿勢を推定する技術です。
人間の姿勢を、関節を線でつないだ棒人間として表現し、そこから画像を生成します。
これによって元画像のポーズをかなり正確に再現することができるのです。
Stable Diffusionでは、ControlNetという機能群の一つとして提供されています。
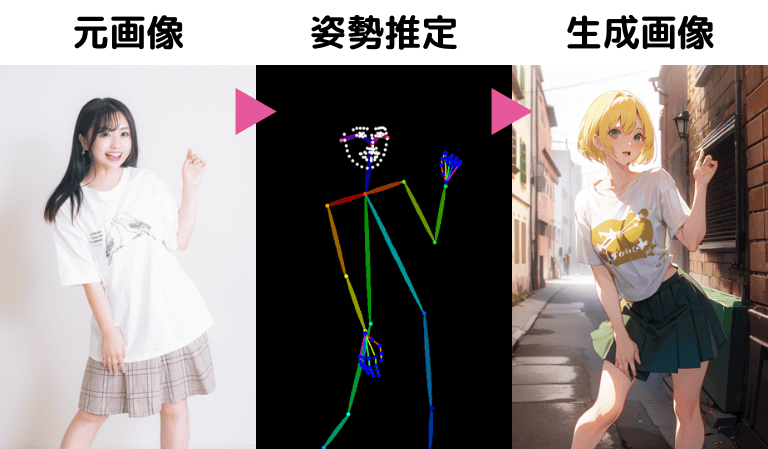
冒頭に紹介した写真を元に、同じポーズの絵を生成するとこうなります。

元画像とかなり近いポーズだね!

全体の姿勢だけではなく、手指や顔の向きもかなり正確に再現できていますね。
次はこのOpenPoseの導入方法と使い方について見ていきましょう。
OpenPoseの導入方法
ここからはStable Diffusion WebUI(AUTOMATIC1111)での操作方法を解説します。
まず、以下の流れでOpenPoseを導入していきます。
- ControlNetの拡張機能をインストールする
- OpenPoseのモデルをダウンロードする
1. ControlNetの拡張機能をインストール
まずは、ControlNetの拡張機能をインストールしていきます。
(すでにインストール済の方は読み飛ばしてOKです。)
① WebUIの「Extensions」タブを開く
② 「Install from URL」タブを開く
③ 「URL for extension’s git repository」に以下のURLを入力
https://github.com/Mikubill/sd-webui-controlnet.git④ 「Install」をクリック
![[Stable Diffusion WebUI] 拡張機能ControlNetをインストール](https://runrunsketch.net/wp-content/uploads/2023/11/auto1111_extentions_cn_install_v3.png)
数秒待つと、インストールが完了し、Installボタンの下に「Installed into C:UsersxxxxStableDiffusionstable-diffusion-webuiextensionssd-webui-controlnet. Use Installed tab to restart.」のようなメッセージが表示されます。
次の手順で、ControlNetを有効化してUIを再スタートします。
① Extensionsの「Installed」タブに移動
② 「sd-webui-controlnet」にチェックが入っていることを確認
③ 「Apply and restart UI」をクリック
![[Stable Diffusion WebUI] 拡張機能ControlNetを適用](https://runrunsketch.net/wp-content/uploads/2023/11/auto1111_extentions_cn_apply_v3.png)
txt2imgの中に、ControlNetという項目が表示されていればOKです。
![[Stable Diffusion WebUI] ControlNetがインストールされたことを確認](https://runrunsketch.net/wp-content/uploads/2023/08/auto1111_extentions_cn_installed.png)
2. OpenPoseのモデルをダウンロード
ControlNetにはOpenPoseやCannyなどいくつかの機能があります。
そして、それぞれの機能に対応する「モデル」をダウンロードする必要があります。
ControlNetの各モデルは、下記の「Hugging Face」のページからダウンロードできます。

「.pth」で終わるファイルがモデルファイルです。
今回はOpenPoseに対応している「control_v11p_sd15_openpose.pth」というファイルをダウンロードしてください。
ファイル名の横のダウンロードボタン「↓」を押すとダウンロードできます。(.yamlファイルはダウンロードする必要はありません。)
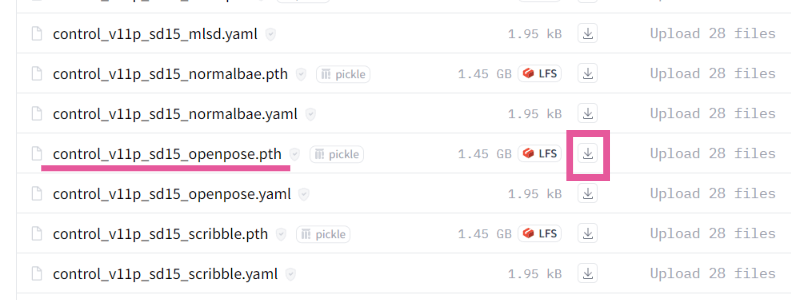
ダウンロードしたファイルは以下の場所に格納します。
Stability Matrixを使っている場合
StabilityMatrix.exeと同フォルダにある「Data」フォルダ > Models > ControlNet
Stability Matrixを使っていない場合
stable-diffusion-webui > extensions > sd-webui-controlnet > models
これで準備OK!
OpenPoseの使い方
ではいよいよOpenPoseを使ってみましょう。
元画像を用意する
ポーズの参照元となる画像を用意します。
写真でもいいですし、イラストでも構いません。著作権には注意しましょう。
著作権を気にしない一番の方法は自分でそのポーズを取って写真に撮ることかもしれません。
この元画像はプリプロセッサで「棒人間」に変換されるので、生成したい画像と元画像の性別を一致させる必要もありません。
つまり、女性の絵を生成したいときに、元画像で男性の写真を使ってもOKということです。

複数人の認識をすることもできます。

ControlNetを有効化する
txt2imgタブを開きます。
「ControlNet」の右端の◀ボタンを押して、メニューを開きます。
「Enable」にチェックを入れると、画像生成するときにControlNetが有効になります。
ControlNetを使わないときには、このチェックを忘れずに外してください。
![[Stable Diffusion WebUI] ControlNetを有効化](https://runrunsketch.net/wp-content/uploads/2023/08/auto1111_controlnet_enable_v2.png)
Control Typeで「OpenPose」を選択する
「ここに画像をドロップ-または-クリックしてアップロード」のところに、元絵とする画像をアップロードします。
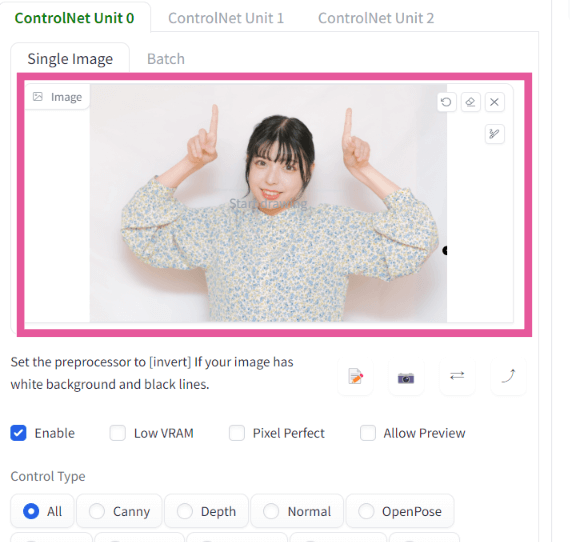
そして、
①Control Typeで「OpenPose」を選択します。
②すると、自動的にPreprocessorが「openpose_full」に、Modelが「control_v11p_sd15_openpose」に設定されると思います。
もしModelがNoneのままになってしまうときは、右にある「リフレッシュボタン」を押してから、再びOpenPoseを選択してください。
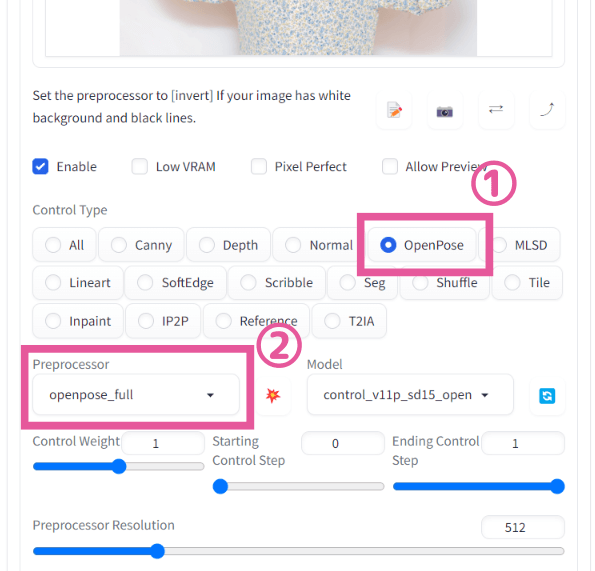
ここで、②の「Preprocessor」(プリプロセッサ)に注目してみましょう。
プリプロセッサは、画像を解析して棒人間を抽出する役割を担います。
プルダウンを開いてみると6種類ほどあることがわかります。
…何が違うわけ?
棒人間として抽出する部位や手法の違いです。
商用利用可能で最新バージョンのdw_openpose_fullがおすすめです
| dw_openpose_full | オススメ。 全身+顔(表情)+手。「DW Pose」という技術を使っている最新のプリプロセッサ。 |
| openpose | 全身 |
| openpose_face | 全身+顔(表情) |
| openpose_faceonly | 顔(表情)のみ |
| openpose_full | 全身+顔(表情)+手 |
| openpose_hand | 全身+手 |
この中では、dw_openpose_fullがおすすめです。最新のプリプロセッサであることも理由ですが、商用利用可能なライセンスだからです。
ということで、dw_openpose_fullを選択♪
あとは普通にプロンプトを入力して画像生成します。
プロンプトで表現が難しい場合もあると思いますが、可能な限りプロンプトは指定した方が思い通りのポーズになります。
ここでは以下のようなプロンプトを入力しました。
girl,brown hair, short hair, smile, white shirt, white background, index finger raised,
生成した画像がこちらです。かなり正確にポーズが再現されていますね。
別の画像からOpenPoseで生成した画像も、参考として載せておきます。



img2imgとの違い
img2imgでも同じようにできないの?
わざわざOpenPoseを使わなくてもimg2imgでうまくできないのかな?と思った人もいるかもしれませんね。
img2imgの場合、姿勢(ポーズ)だけではなくて、人物の輪郭やタッチ、色の情報も参考にしてしまうので、「ポーズは参考にしたいけど、キャラは全然別にしたい」というケースが結構難しいのです。

そのため、キャラの全体的な外見ではなく、ポーズだけを参考にしたいというケースはOpenPoseの方がうまくいきます。
OpenPoseのライセンス
最後にOpenPoseのライセンスについて述べておきます。
筆者は法律の専門家ではないため、以下の情報は参考にとどめてください。
商用利用の際には、ご自身でしっかりとライセンスを確認いただくようお願いいたします。
dw_openpose_fullでは、DW Poseという技術を使っており、これはApache License 2.0(アパッチ ライセンス)というライセンスで提供されています。
これは無償・無制限で商用利用可能なライセンスです。
一方、dw_openpose_full以外のプリプロセッサについては、商用利用する際に有料となる別のライセンスが適用される可能性があります(はっきりとした確証が得られませんでした)。
そのため、商用利用を考えているならば、dw_openpose_fullを使った方がよい、というのが私の見解です。
dw_openpose_fullは優れたプリプロセッサなので、個人利用であってもオススメです
なお、「Checkpoint」はまた別のライセンスになりますので、そちらについては下記の記事を参考にしてください。

まとめ
プロンプトだけで表現するのが難しいポーズは、ControlNetの「OpenPose」という機能を利用するとよいでしょう。
写真やイラストの人物のポーズを参考にして画像生成できるので、かなり正確にポーズの再現が可能です。(ただし、手指に関してはなかなか難しいのが現状です)
これでまた一つ、思い通りの絵に近づいたぞー♪
Stable Diffusionには便利機能がたくさんあるので、適材適所で活用していきましょう!
そのほかのControlNetの機能についてはこちらもご覧ください。




コメント
初めまして。上記の記事に従って最後の操作まで行ってみましたが、「generate」を押しても画像が生成されません。また、下記のようなエラーが出てしまいました。
ゲーミングPCを使用している為、GPUメモリーが足りないという事はないと思いますが、対処法が分からないので、可能でしたら対処方法を教えて頂けますと幸いです。宜しくお願いいたします。
OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 3.40 GiB already allocated; 0 bytes free; 3.46 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Time taken: 10.8 sec.
A: 3.40 GB, R: 3.46 GB, Sys: 4.0/4 GB (100.0%)
コメントありがとうございます。
エラーメッセージを見る限りでは「メモリ不足」のエラーが発生したようです。
(「OutOfMemoryError」はメモリ不足のエラーです)
「…(GPU 0; 4.00 GiB total capacity;…」とありますので、VRAM(グラフィックボードのメモリ)は4GBだと思われます。
Stable Diffusion WebUIは4GBでも動作しますがかなりギリギリのメモリですので、まずは下記の記事で対策を試していただくことをオススメします。
どうぞよろしくお願いいたします。
https://runrunsketch.net/sd-memory-optimize/