

話題のStable Diffusionを無料で使ってみたいんだけど…
Google Colabを使うと完全無料でStable Diffusionを楽しめます♪
2022年ごろから急速に盛り上がりを見せている「画像生成AI」ですが、そのきっかけとなったのが「Stable Diffusion(ステイブル ディフュージョン)」の登場です。
Stable Diffusionは、誰もが無料で使える画像生成AIです。
現在展開されているさまざまなAIイラストサービスにも、その裏側にはStable Diffusionが使われていることが多いです。
この「Stable Diffusion」は誰でも無料で使えるのですが、動かすためには高性能なパソコンが必要になります。事務用の普通のパソコンだとまともに動かすことができません。
いや、私のパソコン、性能しょぼいですから…💦
でも、安心してください。低スペックなパソコンでもStable Diffusionを動かすことはできます。
この記事では、その方法の1つ、「Google Colaboratory」を利用してStable Diffusionを完全無料で動かす方法を解説します。
その他の方法についてはこちらの記事を参考にしてみてください。現在はどちらかというとこれらの方法の方がオススメです👇

なお、現在、Stable Diffusionは「WebUI」という視覚的な画面を使って操作するのが主流なのですが、本記事で解説する方法はWebUIは使いません。
理由は、無料プランのGoogle Colaboratoryでは「WebUI」を動かすことが禁止されているからです。
そのため、本記事では「完全無料」でStable Diffusionを動かすために、「WebUI」を使わない方法を丁寧に解説していきます。
順番にわかりやすく解説するので安心してくださいね😊
- Stable Diffusionを低スペックなパソコンで完全無料で使いたい人
- WebUIを使わないStable Diffusionの使い方を知りたい人
本記事では、画像生成AIの基本となる「テキストから画像を生成する方法:txt2img(テキストtoイメージ)」について解説しています。
「画像から画像を生成する方法:img2img(イメージtoイメージ)」については、こちらの記事を参照してください。

Stable Diffusionとは
まず、Stable Diffusionをよく知らない人のために、Stable Diffusionの概要や仕組みを簡単に紹介します。
「もう知っているよ」という人は読み飛ばしてOKです。
概要

Stable Diffusion(ステイブル ディフュージョン)は、誰もが無料で使える画像生成AIです。
それまでもMidjourneyやDALL・Eなどの画像生成AIはありました。Stable Diffusionが革新的だったのは「オープンソース」つまり「誰でも無償で利用できるようにソースコードを公開した」という点です。「ソースコード」というのはソフトウェアの設計図のようなものですから、全世界に設計図を公開したということですね。
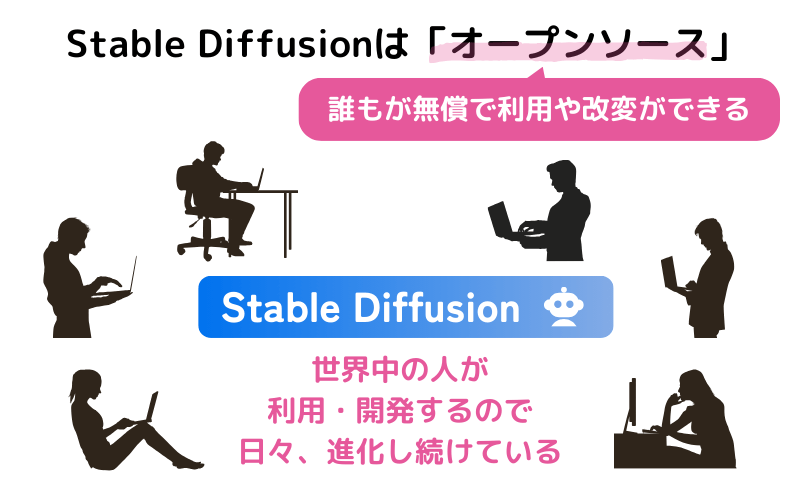
通常、企業などで開発したソフトウェアはソースコードを公開なんてしません。そんなことをしたら、たちまち類似ソフトが作られて、自社のソフトが売れなくなってしまうからです。
しかし、Stable Diffusionは「オープンソース」としたことによって、世界中の誰もがStable Diffusionの仕組みまで深く理解することができました。そして、その技術を応用した派生したモデルやサービスが次々と生まれていったのです。
現在でもStable Diffusionは世界中の有志によって進化し続けています。
Stable Diffusionでどんなことができるのかざっくり知りたい方はこちらの記事をご覧ください。

どんな仕組み?
Stable Diffusionはどんな仕組みで動いているのでしょうか?
次々に画像が生成できるなんて…とっても不思議だと思いませんか?
ここでは、数式はいっさい使わずにその仕組みをざっくりと解説します。
AIの基本的な仕組み
Stable Diffusionというのは「機械学習」というAI技術を利用しています。
機械学習は、お手本となる大量のデータ使ってAIを訓練し、目的を達成する仕組みのことです。
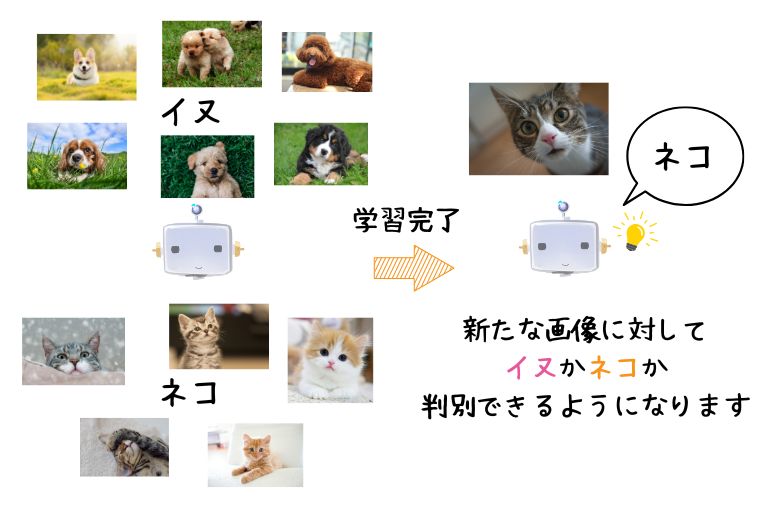
たとえば、イヌとネコの画像を見分けるAIを作ろうと思った場合、大量のイヌとネコの画像をAIに与えて学ばせます。これはイヌ、これはネコ…という感じでAIを鍛えると、イヌとネコを見分けられるAIができるというわけです。
人間の「テスト勉強」に似ていますね♪
Stable Diffusionの仕組み
先ほどの「イヌとネコを見分けるAI」であれば、イヌとネコのラベルをつけた画像を大量に学習させればよさそうだと想像はつくかもしれません。
ですが、Stable Diffusionのような「画像を生成する」という目的のAIを訓練しようとした場合、いったいどんなデータを使ってどう訓練すればいいのか、なかなか想像がつきませんよね。
Stable Diffusionは「拡散モデル(Diffusion Model)」という仕組みを使った画像生成AIです。
ここでは「きれいなチョウ🦋の画像を生成するAIをつくりたい!」という前提で拡散モデルの仕組みを見ていきましょう。
※以下の説明ではわかりやすさを優先するため、正確ではない表現が含まれていることをご了承ください。
まず、たくさんのチョウ🦋の画像をAIの「学習データ」として用意します。AIはこの画像をもとにして、チョウの描き方を学ぶわけです。

人間であれば、チョウに特有の構造を見つけようとします。たとえば、胴体を中心に左右に対称に羽があって、頭からは触覚が映えていて、…といった感じですよね。
でも、「拡散モデル」のAIはとてもユニークな学び方をします。
まず、画像に少しずつノイズを加えていきます。そして最終的には完全なノイズになります。

この過程を逆にたどっていけば、つまり、ノイズ画像からノイズを取り除いていけば最終的にきれいな画像が得られます。AIはこのように、少しずつノイズを取り除いていくことで画像を生成する方法を学習します。

この特訓を終えたAIは、ノイズを元にしてきれいなチョウの画像を生成するというスーパー能力を身に着けているわけです💪
あとは、画像生成したいときにランダムなノイズを与えてあげればよいだけです。人間にはただのノイズにしか見えませんが、特訓を終えた画像生成AIには、うっすらと「チョウ」に見えているはずです。画像生成AIはそこから少しずつノイズを取り除き、きれいな画像を描き出すことができるというわけです。

言葉でいうとあっさりしていますが、実はこのAIの学習はすごく大変です。まず、相当の数の画像を集めないといけません。Stable Diffusionではなんと50億枚の画像を学習したと言われています。そして、これだけの画像を学習させるためには、非常に高スペックなコンピュータが必要です。このようなことを利用者一人ひとりが行うわけにはいかないので、すでに学習を終えているAIを共有できるようになっています。
このような学習済みのAIモデルを公開してくれている団体のひとつが「Hugging Face」です。
Stable Diffusionの使い方
Stable Diffusionを使うには「公開されている学習済のAIモデルをダウンロードして、プロンプトを与えて画像を生成すればよい」ということになります。
動かす環境は大きく2つ
「Stable Diffusion」には大きく3つの利用形態があります。
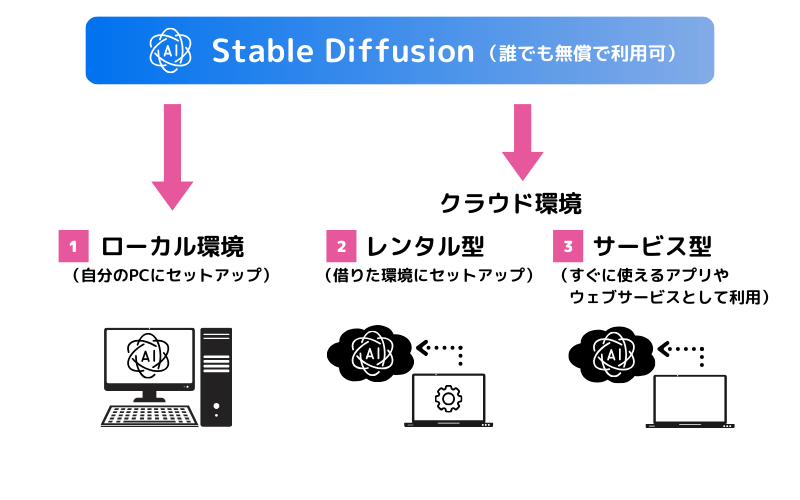
「①ローカル環境」が最も自由度の高い方法ですが、高性能なGPUを搭載したPCが必要になることから金銭面でのハードルが高いと言えます。
15~20万円くらいのPCが必要です…
う…そんなお金ないです
一方、この記事でご紹介するのは②の方法です。「Google Colaboratory」は無料ということもあって、やや制約はありますが、まずはGoogle Colaboratoryで試してみて、物足りなくなってきたら①の方法に移行するのでも遅くはありません。
「Google Colaboratory」で動かす
Google Colaboratory(グーグル コラボラトリー)は、プログラムをGoogleのクラウド上で動かすことができるサービスです。
自分のパソコンでプログラムを動かそうとすると色々と設定が必要になりますが、このGoogle Colaboratoryはクラウド上ですでに用意されている環境で動かすので面倒な設定は必要ありません。初学者であっても1分でプログラムを動かすことができるのが魅力です。
楽チンだね♪
Stable Diffusionを動かすときには、「WebUI」という視覚的なインターフェースを使う方法もあるのですが、2023年4月ごろからGoogle Colaboratory上で「WebUI」を動かそうとすると警告が出るようになりました。(WebUIはマシンパワーが必要なので、Googleのリソースを圧迫してしまうためと思われます)
そのため、本記事ではWebUIを使わない安全な方法で行います。ちょっとだけプログラムを書いていきますが、順番に進めていけば大丈夫です✨
難しくない…?
丁寧に解説するので安心してください😊
では、楽しみながらいってみましょう♪
本家Stable Diffusionモデルで画像を生成する
「Stable Diffusion」にはさまざまな派生モデルがあり、それぞれに絵柄が違います。
皆さんいろいろと絵の好みはあると思いますが、まずは全体的な流れを把握するためにStable Diffusionの本家モデルを使って画像生成してみます。
そのあと、別のモデルを選択したり、設定を変更して出力を調整したりしてみましょう♪
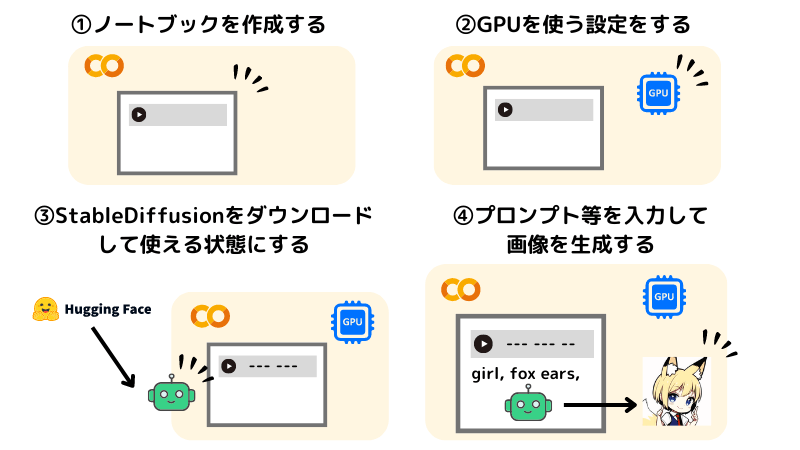
まずは全体像です。大まかな流れはこのような感じになります。
① Google Colaboratoryのノートブックを作成する
② GPUを使う設定をする
③ StableDiffusionをダウンロードして使える状態にする
④ プロンプトなどを入力して画像を生成する
それでは、順番に進めていきましょう。
みんなも私と一緒にやってみよう♪
①Google Colaboratoryのノートブックを作成する
![[ColabでStable Diffusion] ①ノートブックの作成](https://runrunsketch.net/wp-content/uploads/2023/05/sd_colab_flow_1.png)
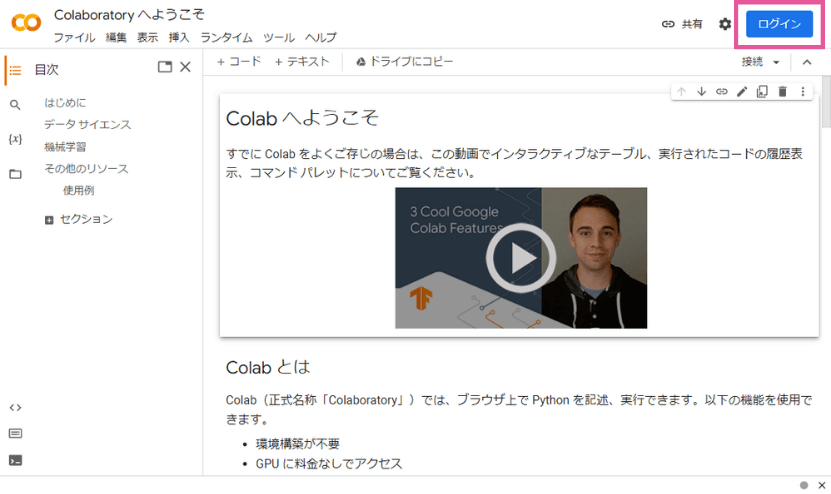
まずは、Google Colaboratoryのウェブページを開きます。
ログインしていない場合は、このような画面になるはずです。右上のログインボタンを押して、Googleアカウントでログインしましょう。
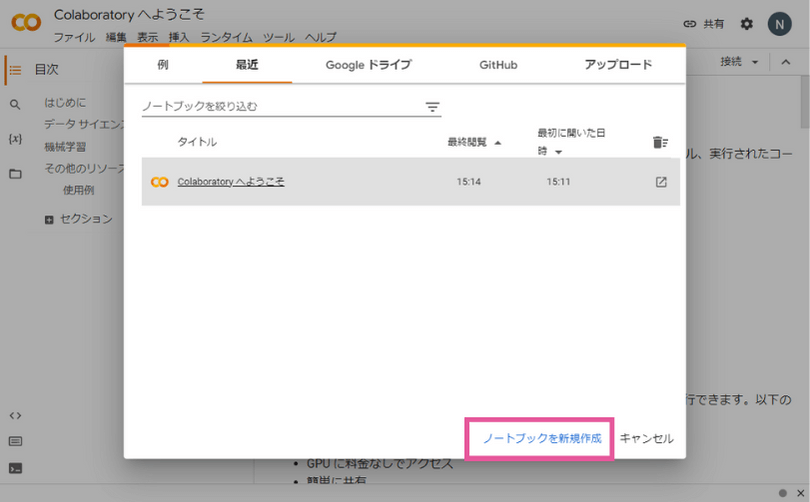
ログインすると、このようにノートブックを選択する画面になります。ノートブックというのは、Google Colaboratoryでプログラムを動かすファイルのことです。
今回は「ノートブックを新規作成」しましょう。
すると、このように新しいノートブックが作られます。
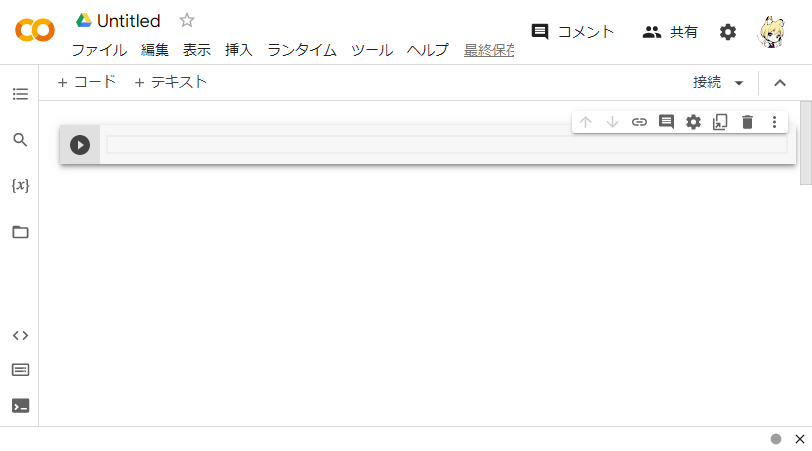
ノートブックのタイトル(ファイル名)は最初は「Untitled」のようになっているので、わかりやすいタイトルを変更すると良いです。ここでは「はじめてのStableDiffusion」としておきます。
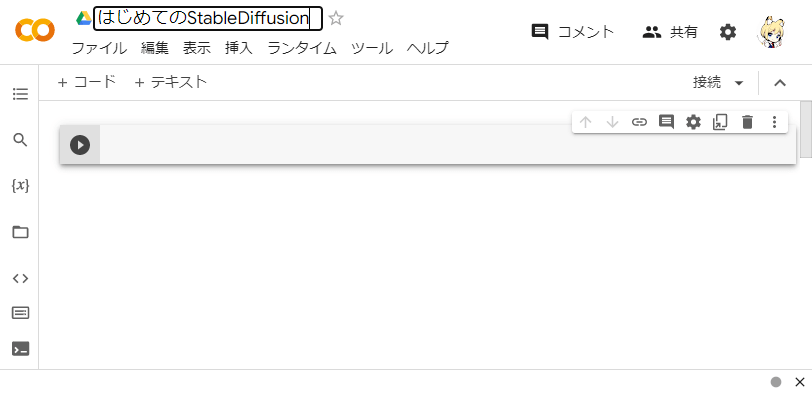
このあとは、灰色の四角の領域(「セル」といいます)にStable Diffusionを動かすためのプログラムを書いていきます。
プログラムを書くというと難しいイメージがあるかもしれませんが、難しくないので本記事の通りに進めていけば大丈夫です😊
補足:Google Colabでのプログラムの実行方法
本題の前に、Google Colabの基本的な使い方を説明します
灰色の四角の領域(「セル」)にプログラムを書いて、セルの左端にある▶ボタンを押してプログラムを実行します。(「▶ボタン」の代わりに、キーボードの「Shift+Enterキー」でもOK)
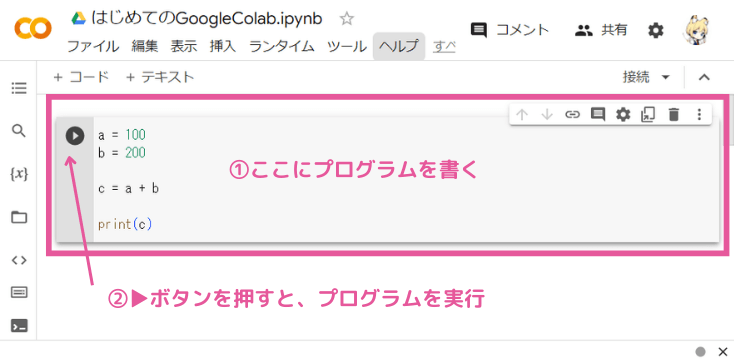
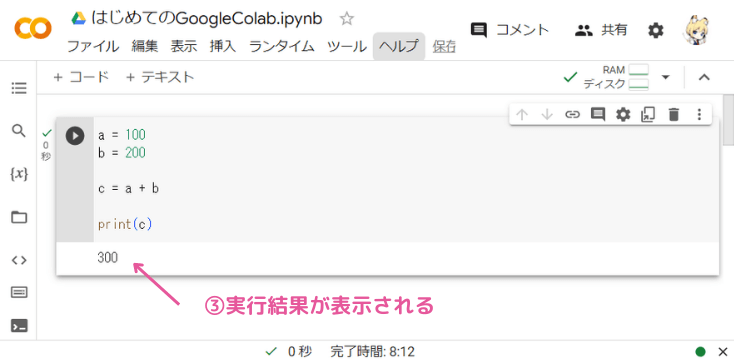
プログラムの実行結果は、セルのすぐ下に表示されます。
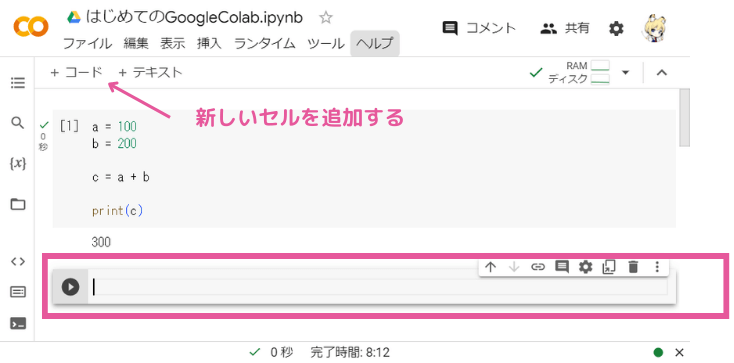
新しいセルは上部の「+コード」を押すと挿入できます。
今回はこれだけ覚えておけばOKです👌
②GPUを使う設定をする
![[ColabでStable Diffusion] ②GPUの設定](https://runrunsketch.net/wp-content/uploads/2023/05/sd_colab_flow_2.png)
では、本題に戻りましょう。
Stable Diffusionが動くときには、内部でものすごい量の計算が走ります。そのため、通常のパソコンの処理装置(CPU)だけでは力不足で、GPUという特別な処理装置を使います。
このGPUにもピンからキリまであるのですが、それなりに良い性能のGPUはなかなか良いお値段がします…。ところがありがたいことに、Google Colaboratoryでは無料でGPUを使えるのです。
プログラムを書いていく前にその設定を行います。
上部メニューの「編集」―「ノートブックの設定」を選択します。
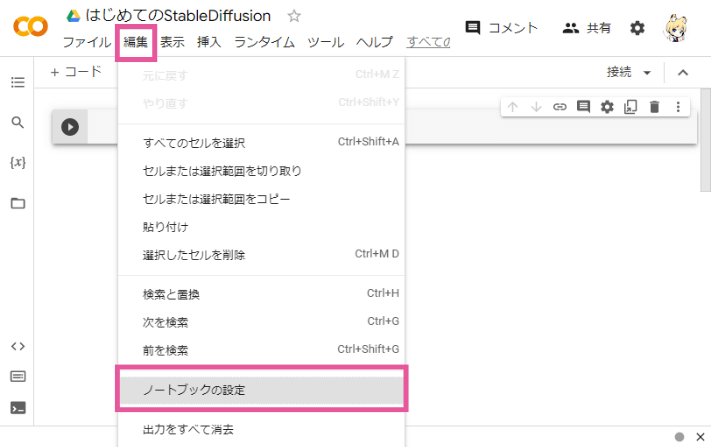
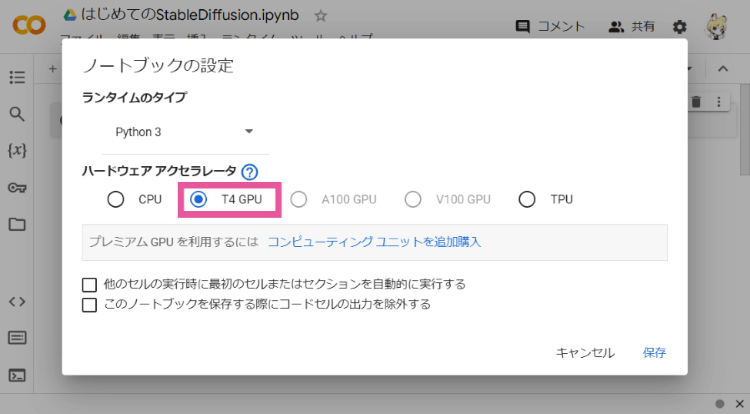
ハードウェア アクセラレータを「GPU」に、GPUのタイプを「T4」に変更して「保存」を押します。
※GoogleColab有料版にすると、GPUのタイプをもっと高性能なものに設定できますが、無料だと「T4」しか選べません。
念のため、ちゃんとGPUを使う設定にできたか確認してみましょう。ノートブックのセルに以下のように入力して実行してみてください。
!nvidia-smi下のような表示が出ればきちんとGPUを使う設定になっています。
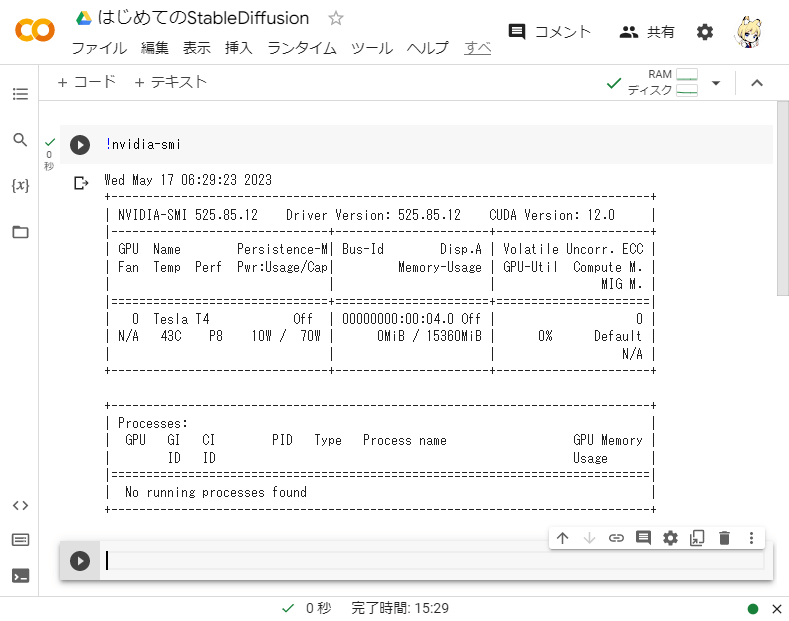
もしcommand not found のように表示されてしまった場合は、GPUの設定になっていませんので、もう一度本項目の設定を確認してみてください。
③Stable Diffusionをダウンロードして使える状態にする
![[ColabでStable Diffusion] ③Stable Diffusionのダウンロード](https://runrunsketch.net/wp-content/uploads/2023/05/sd_colab_flow_3.png)
Stable Diffusionを使うには、「🤗Hugging Face」が提供してくれているDiffuserという便利な仕組みを使います。
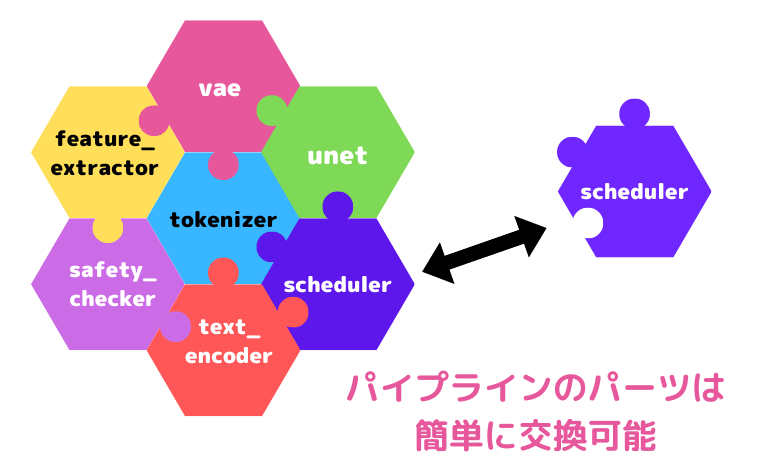
Stable Diffusionというのは、モデルやスケジューラなどといった複数のパーツが組み合わさって実現されているのですが、Diffuserはそれらを簡単にダウンロードしたり組み替えたりできる仕組みです。
まず、Stable Diffusionを動かすために必要なライブラリをインストールします。ライブラリというのは、どこかのステキな人が作ってみんなのために公開してくれている便利なプログラムのことです。遠慮なく使わせていただきましょう。Diffuserもそんなステキなライブラリのひとつです🥰️
では、新しいセルに以下のコードを入力して実行してみましょう(コピペでOK)。Google Colaboratoryの環境に自動的にインストールが開始されます。ここでは「diffusers」「accelerate」「transformers」という3つのライブラリをインストールしています。
!pip install --upgrade diffusers accelerate transformersSuccessfully installed…
のようなメッセージが表示されたら無事インストールは完了です。これでStable Diffusionを使う準備は整いました✨
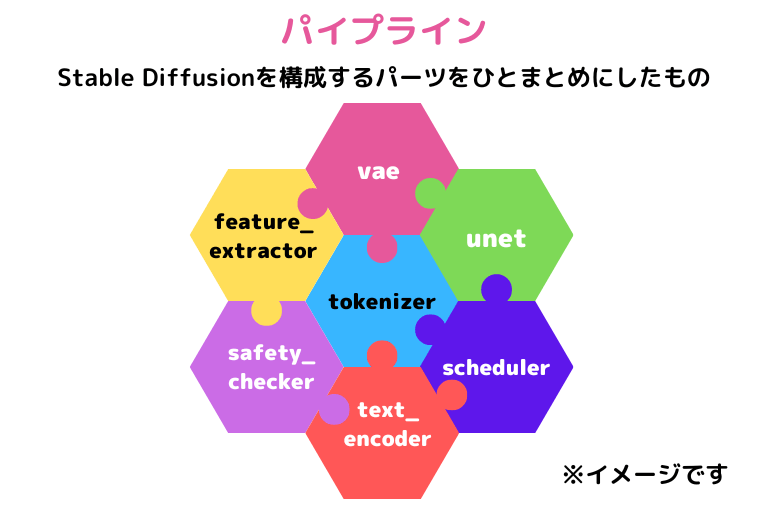
それでは、Diffusersを使って、Stable Diffusionをダウンロードしていくわけですが、最初に「パイプライン」というものを作成します。このパイプラインはモデルやスケジューラなどStable Diffusionを構成するパーツをひとまとめにしたものとイメージしてください。
それでは、新しいセルに、以下のコードを入力して実行してみましょう。コピペでOKです。
from diffusers import StableDiffusionPipeline
# 利用したいAIモデル
# Stable Diffusionにはさまざまな派生モデルがあります
model_id = "runwayml/stable-diffusion-v1-5"
# パイプラインの作成
pipeline = StableDiffusionPipeline.from_pretrained(model_id)
# GPUを使うように変更
pipeline = pipeline.to("cuda")from diffusers import StableDiffusionPipelinediffusersというライブラリから「StableDiffusionPipeline」というモノを使えるように準備しています。
model_id = "runwayml/stable-diffusion-v1-5"Stable Diffusionにはさまざまな派生モデルがあります。それらのモデルは公開されていて、ここではv1.5のモデル名をmodel_idに定義しています。
pipeline = StableDiffusionPipeline.from_pretrained(model_id)モデル名を指定して、そのモデルのパイプラインを作成しています。model_idを変更すれば、別のモデルのパイプラインを作成することもできます。
pipeline = pipeline.to("cuda")パイプラインを動かすときにGPUを使うように設定しています。cuda(クーダ)というのはGPUのプログラム開発環境の名前です。
これでStable Diffusionを使う準備ができました!
④画像を生成する
![[ColabでStable Diffusion] ④画像の生成](https://runrunsketch.net/wp-content/uploads/2023/05/sd_colab_flow_4.png)
モデルをダウンロードして画像生成の準備が整いました。いよいよ画像を生成してみましょう。
Stable Diffusionでも画像生成の考え方はNovelAIなどと同じで、プロンプト(呪文)やその他のパラメータをAIに指定して画像生成します。(テキストから画像を生成するので「txt2img」と呼ばれます)
まずは難しい設定はせずに、プロンプトだけで画像生成してみましょう。
プロンプトは言葉で描きたいものを表現します。基本的には「英語」で書きます。
ここでは、「a robot enjoying wine in a luxury hotel room(高級なホテルルームでワインを楽しむロボット)」としてみます。
新しいセルに以下のソースコードを入力して実行してみてください。
# プロンプト
prompt = "a robot enjoying wine in a luxury hotel room"
# 画像を生成
image = pipeline(prompt).images[0]
# 画像を表示
imageおそらく20秒~30秒前後で画像が生成されると思います。
私はこんな画像が生成されました。
皆さんはどうでしたか?面白い画像は生成できましたでしょうか😊?

ここまでが、基本的な画像生成の流れです。意外と簡単でしょう?
画像の生成を高速化する
ここまでで画像生成はできるのですが、1枚生成するのに30秒もかかるのはちょっと遅いと思いませんか?
プログラムを少しだけ変更して、画像生成を高速化しましょう!
次に説明するプログラムの変更で3秒前後で画像生成できるようになります。
方法1:計算の精度を落として高速化
まず1つめの変更です。画像生成のときの計算の精度をfloat32からfloat16に落とすことで高速化します。精度を落とすといっても、画像が荒くなってしまうということはありません。見た目はまったく変わらないです。この方法はHugging Face公式も強く推奨している方法です。
「③Stable Diffusionをダウンロードして使える状態にする」で実行したセルを以下のように変更して、再実行してみましょう。赤字が変更箇所です。
from diffusers import StableDiffusionPipeline
import torch
# 利用したいAIモデル
# Stable Diffusionにはさまざまな派生モデルがあります
model_id = "runwayml/stable-diffusion-v1-5"
# パイプラインの作成
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
# GPUを使うように変更
pipeline = pipeline.to("cuda")これで以下のセルを再び実行して画像生成してみましょう。10秒前後にまで時間を短縮できるはずです🚀
# プロンプト
prompt = "a robot enjoying wine in a luxury hotel room"
# 画像を生成
image = pipeline(prompt).images[0]
# 画像を表示
image方法2:ステップ数の少ないスケジューラにする
さらに高速化してみましょう。Stable Diffusionではノイズから1ステップずつだんだんときれいな画像を作っていくわけですが、デフォルトだと「50ステップ」かかります。これはノイズ除去の手法(スケジューラ)として「PNDMScheduler」というものを使っているためです。
もっと高速なスケジューラに変更することで、ステップ数を減らすことができ、結果的に画像生成が早くなります。
「スケジューラ」は「パイプライン」を構成するパーツのひとつですが、簡単に別の種類のスケジューラに交換することができます。
先ほどの方法1で変更したセルをさらに下記のように変更して、再実行してみてください。
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
# 利用したいAIモデル
# Stable Diffusionにはさまざまな派生モデルがあります
model_id = "runwayml/stable-diffusion-v1-5"
# パイプラインの作成
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
# スケジューラを変更
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
# GPUを使うように変更
pipeline = pipeline.to("cuda")これで再び画像生成してみましょう。画像生成時にステップ数を指定することができるのですが、20ステップにしてみましょう。
# プロンプト
prompt = "a robot enjoying wine in a luxury hotel room"
# 画像を生成
image = pipeline(prompt, num_inference_steps=20).images[0]
# 画像を表示
imageこれで3秒前後で画像生成できるようになるはずです🚀
プログラム全文
ここまでの最終的なプログラムをまとめておきます。
必要なライブラリの準備
!pip install --upgrade diffusers accelerate transformersStable Diffusionをダウンロードして使える状態にする
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
# 利用したいモデル
model_id = "runwayml/stable-diffusion-v1-5"
# パイプラインの作成
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
# GPUを使うように変更
pipeline = pipeline.to("cuda")画像の生成(プロンプトは自由に変更してOK)
# プロンプト
prompt = "a robot enjoying wine in a luxury hotel room"
# 画像を生成
image = pipeline(prompt, num_inference_steps=20).images[0]
# 画像を表示
imageStable Diffusionでの画像生成の流れはつかめましたか?それでは、次は別のモデルを使ってみましょう。
絵柄(モデル)を変える
ここまでは本家のStable Diffusionを使って画像生成してきました。
Stable Diffusionの素晴らしい点は、「モデル」を変更することで「絵柄」を簡単に変更できるということです。
モデル探しについては、下記の記事で詳しく解説しています。アニメ系のおすすめモデルも紹介していますので、よろしければ参考にしてみてください。

「るんるんスケッチ」は主にアニメ系の画像生成を解説するブログですので、Stable Diffusionの派生モデルの中でもアニメ系でよく使われるモデルで画像生成してみましょう。
「Counterfeit」というモデルを使います。

流れは先ほどと同じです。
必要なライブラリのダウンロードは終わっているので、③のパイプラインを作成する手順からで大丈夫です。
ただし、Google Colabの環境は時間が経つともろもろがリセットされてしまうので、もし③の実行でエラーが出てしまう場合は、もう一度ライブラリをインストールする下記のセルを再実行してみてください。
!pip install --upgrade diffusers accelerate transformers③Stable Diffusionをダウンロードして使える状態にする
以下のコードを実行してください。よく見るとわかりますが、基本的にはmodel_idを変更しているだけです。このようにモデル名を変更するだけで、さまざまなモデルを使えるところがDiffusersの便利なところです。
from diffusers import StableDiffusionPipeline
# 利用したいAIモデル
# Stable Diffusionにはさまざまな派生モデルがあります
model_id = "gsdf/Counterfeit-V2.5"
# パイプラインの作成
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
# GPUを使うように変更
pipeline = pipeline.to("cuda")④画像を生成する
画像生成も基本的には先ほどと同じです。今回はプロンプトを変えてみましょう。皆さんも、妄想力を働かせて好きなプロンプトを入力してみてください🥰️
今回はプロンプトだけではなく、出力サイズやネガティブプロンプトなどの各種パラメータを指定してみます。
prompt = "((masterpiece,best quality)),1girl, solo, school uniform, serafuku, black hair, skirt, sailor collar, long hair, blunt bangs, neckerchief, long sleeves, smile, blue sky, pleated skirt, cowboy shot"
n_prompt = "EasyNegative, extra fingers,fewer fingers, "
cfg_scale = 10 # スケール
steps = 50 # ステップ
width = 512 # 出力画像の幅
height = 512 # 出力画像の高さ
# 画像を生成
image = pipeline(prompt=prompt,
negative_prompt=n_prompt,
guidance_scale=cfg_scale,
num_inference_steps=steps,
width=width,
height=height).images[0]
# 画像を表示
image
わぉ!かわいいですね🥰️
画像を保存する
これは画像が表示されているだけなので、残しておきたい場合はファイルとして保存する必要があります。
プログラム中の「image」という変数が生成された画像を表しています。
image.save(“保存先のパス”)で、Googleドライブ内の任意の場所に画像を保存することができます。
まずは、Googleドライブを「マウント」することで、Google ColabからGoogleドライブを認識させます。手順は次の通りです。
Google Colabの左側メニューの「ファイル」をクリックします。
「ドライブをマウント」をクリックします。
Googleドライブへのアクセスを許可するか聞いてくるので、「Googleドライブに接続」をクリックします。
少し待つと、Googleドライブに接続され、左側メニューのフォルダーに「drive」というのが表示されます。これがGoogleドライブを表しています。
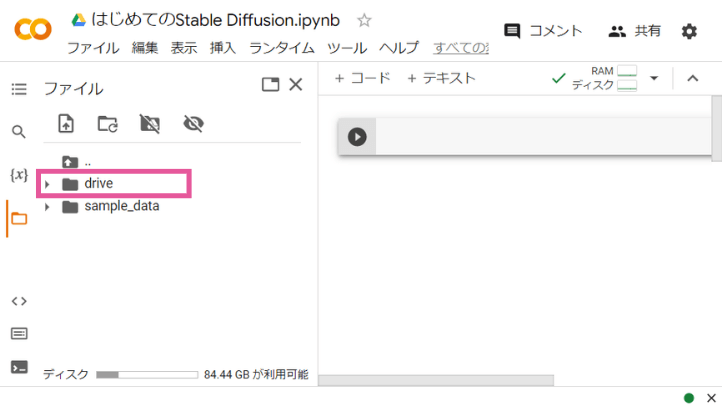
これで保存の準備はOK!
あとは、imageを生成したあとに、次のプログラムを実行すれば画像をファイルとして保存できます。
なお、プログラム中の「ここに保存したいフォルダのパスを貼り付ける」の部分は、皆さんの保存したいフォルダのパスに置き換えてください。
「好きなファイル名」も拡張子付きのお好きなファイル名に置き換えてください。(例えば、image.pngなど。)
# 保存したいフォルダのパス
path = "ここに保存したいフォルダのパスを貼り付ける"
filename = "好きなファイル名"
# 保存
image.save(f"{path}/{filename}")保存したいフォルダのパスについて
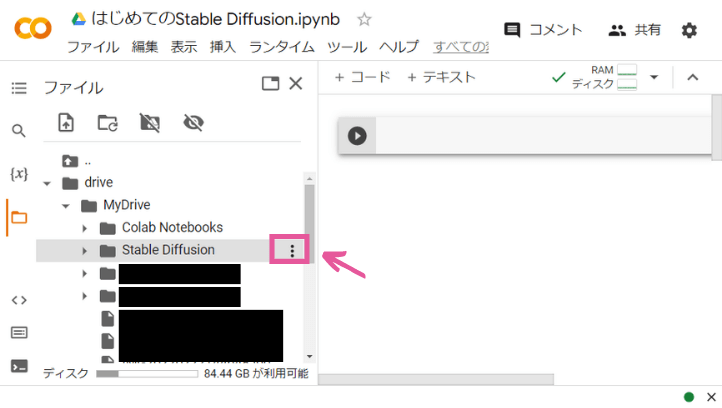
左側メニューの「drive」の左端の▼を押すと、下の階層を開けます。画像を保存したいフォルダを開きましょう。そのフォルダの右端の「3つの点」ボタンを押して、「パスをコピー」をクリックします。すると、そのフォルダーのパスがクリップボードにコピーされます。
保存するたびにいちいちファイル名を考えるのは面倒だという人は、以下のようにすれば現在時刻をファイル名にすることができて便利かもしれません。
import datetime
# 保存したいフォルダのパス
path = "ここに保存したいフォルダのパスを貼り付ける"
# 現在時刻を取得(日本時間)
time = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
time_str = time.strftime("%Y%m%d%H%M%S")
# 保存
image.save(f"{path}/{time_str}.png")もっと快適に使うなら
本記事では、完全無料でStable Diffusionを使う方法を解説しました。これでStable Diffusionの魅力を十分に体験することができるはずです。
ですが、Google Colabは無制限で画像生成できるわけではなく、GPUを使いすぎると一時的にストップがかかってしまいます。
Stable Diffusionをもっと快適に使うなら、ローカルPCで動かすことをオススメします。視覚的なWebUIを使うこともできるので、さらに楽しく画像生成を楽しむことができます✨
Stable Diffusionに最適なパソコン選びについては、こちらの記事を参考にしてみてください。

Stable Diffusion以外の方法も
「やっぱりプログラムを実行して画像生成するのは大変だよ…😅」という人は、ウェブブラウザから簡単に画像生成を行うことのできる「AIイラストサービス」を使うことをおすすめします。
私が特におすすめなのは「NovelAI」と「にじジャーニー」です。利用料はかかりますが、初心者でも使いやすく、品質の高いイラストをさくさくと描くことができます🎨スマホでも使えるので、いつでもどこでもAIイラストを楽しめますよ♪
興味のある方はこちらの記事を参考にしてみてください。




コメント
すいません。最後の画像の保存のところを、以下のコードでやってみたところエラーを吐かれました。何かお分かりでしたら、お教えいただけませんか?
*実行コード
import datetime
# 保存したいフォルダのパス
path = “/content/drive/MyDrive/AIイラスト”
# 現在時刻を取得(日本時間)
time = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
time_str = time.strftime(“%Y%m%d%H%M%S”)
# 保存
image.save(f”{path}/{time_str}.png”)
*出力エラー
—————————————————————————
NameError Traceback (most recent call last)
in ()
9
10 # 保存
—> 11 image.save(f”{path}/{time_str}.png”)
NameError: name ‘image’ is not defined
申し訳ありません。最初のコードから順にやったら解決しました。お騒がせしてほんとうにすいません。
コメントありがとうございます。解決したようで安心しました。
* 出力エラー
NameError: name ‘image’ is not defined
発生していた上記のエラーは、「image」が存在しないよ、というエラーです。
原因としては、imageを作っている下記のコードを含むセルが未実行の状態だったと考えられます。
————
# 画像を生成
image = pipeline(prompt=prompt,
negative_prompt=n_prompt,
guidance_scale=cfg_scale,
num_inference_steps=steps,
width=width,
height=height).images[0]
————
ですので、ご対応いただいたように「最初からコードを順に実行していく」という対応でOKです。
Google Colabは少し時間が立つと状態がリセットされてしまうので、エラーになった場合は最初から順にコードを再実行してみると良いかもしれません(^^)
大変失礼ながら質問があります。ご親切な有志の方が作ってくれた「Google Colab お手軽LoRA(v2.0)」『https://colab.research.google.com/drive/1_a_taV-0rqBU60bzHHiPsTi24-hiG3QW#scrollTo=3CWWYh-DzvK0』 で作ったオリジナルLoraは、紹介されているコードをいくらか改良すれば使えるようになりますか?
様々なサイトをめぐりましたが、まったく情報を獲得できずにいまして、このような大変ご失礼な質問をさせていただきました。専門外、対応外のご質問でありましたら無視してください。可能でありましたらご教授いただければ幸いです。
コメントありがとうございます。返信遅くなり申し訳ありません!
こちらの記事が参考になるかもしれません。
diffusers で Lora (safetensors) を読み込んで生成する方法
https://qiita.com/Limitex/items/275d91dd4acdbf57b5f4
下記のようなコードで試したところ、Civitaiで公開されているLoRAであれば動きました。
私は「Google Colab お手軽LoRA(v2.0)」を使ったことがありませんので、見当違いの方法でしたら申し訳ありませんが、ご参考になれば幸いです。
import torch
from safetensors.torch import load_file
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
def load_safetensors_lora(pipeline, checkpoint_path, LORA_PREFIX_UNET="lora_unet", LORA_PREFIX_TEXT_ENCODER="lora_te", alpha=0.75):
# load LoRA weight from .safetensors
state_dict = load_file(checkpoint_path)
visited = []
# directly update weight in diffusers model
for key in state_dict:
# it is suggested to print out the key, it usually will be something like below
# "lora_te_text_model_encoder_layers_0_self_attn_k_proj.lora_down.weight"
# as we have set the alpha beforehand, so just skip
if ".alpha" in key or key in visited:
continue
if "text" in key:
layer_infos = key.split(".")[0].split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
curr_layer = pipeline.text_encoder
else:
layer_infos = key.split(".")[0].split(LORA_PREFIX_UNET + "_")[-1].split("_")
curr_layer = pipeline.unet
# find the target layer
temp_name = layer_infos.pop(0)
while len(layer_infos) > -1:
try:
curr_layer = curr_layer.__getattr__(temp_name)
if len(layer_infos) > 0:
temp_name = layer_infos.pop(0)
elif len(layer_infos) == 0:
break
except Exception:
if len(temp_name) > 0:
temp_name += "_" + layer_infos.pop(0)
else:
temp_name = layer_infos.pop(0)
pair_keys = []
if "lora_down" in key:
pair_keys.append(key.replace("lora_down", "lora_up"))
pair_keys.append(key)
else:
pair_keys.append(key)
pair_keys.append(key.replace("lora_up", "lora_down"))
# update weight
if len(state_dict[pair_keys[0]].shape) == 4:
weight_up = state_dict[pair_keys[0]].squeeze(3).squeeze(2).to(torch.float32)
weight_down = state_dict[pair_keys[1]].squeeze(3).squeeze(2).to(torch.float32)
curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).unsqueeze(2).unsqueeze(3)
else:
weight_up = state_dict[pair_keys[0]].to(torch.float32)
weight_down = state_dict[pair_keys[1]].to(torch.float32)
curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down)
# update visited list
for item in pair_keys:
visited.append(item)
return pipeline
# 利用したいモデル
model_id = "gsdf/Counterfeit-V2.5"
# LoRAのファイルパス
# 事前にGoogleDriveにLoRAファイルを格納して、そのファイルのパスを調べておいてください
lora_path = "/content/drive/MyDrive/kanaotsuyuritest.safetensors"
# パイプラインの作成
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
# LoRAを使う
pipeline = load_safetensors_lora( pipeline, lora_path).to("cuda")
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
# GPUを使うように変更
pipeline = pipeline.to("cuda")
# プロンプト
prompt = "ここに好きなプロンプトを入力"
# 画像を生成
image = pipeline(prompt, num_inference_steps=20).images[0]
# 画像を表示
image
お返答いただき、本当にありがとうございます!
試してみます。Civitaiで公開されているLoRAであれば動くのであれば同系統に編集できればいけるかもしれません。ご教授のほどありがとうございました。