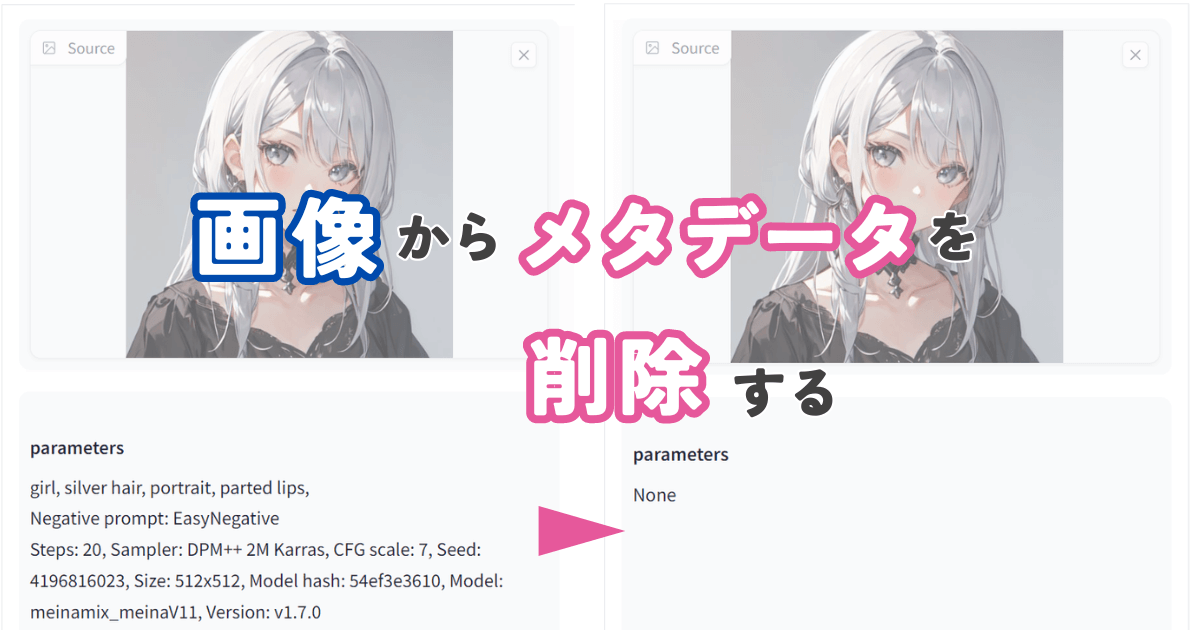
以前の記事では画像ファイルの「メタデータ」について解説しました。

本記事では、この知識を踏まえて、NovelAIの生成画像のメタデータについてさらに深く理解していきましょう。
メタデータについて簡単におさらい
画像ファイルにおける「メタデータ」とは、画像データを説明するためのデータのことです。

特にNovelAIなどの画像生成AIのメタデータには、「プロンプト」や「シード値」「ステップ」などの画像生成時のパラメータ情報が含まれていることがあります。
PNGファイルにおけるデータ構造は、「シグネチャ」と複数の「チャンク」から成ります。
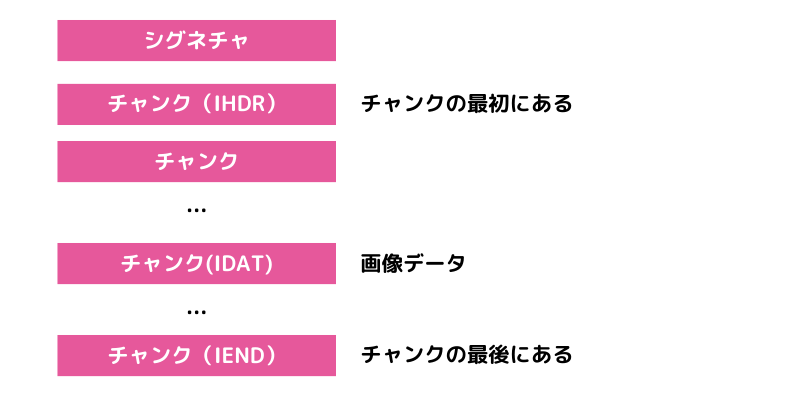
「チャンク」の中身がPNGファイルを理解するポイントになりますが、どのようなチャンクでも必ずこのような構成になっています。
| 名前 | サイズ | 説明 |
|---|---|---|
| Length | 4byte | Chank Dataのサイズ |
| Chank Type | 4byte | チャンクの種類 |
| Chank Data | 0byte以上 | データ本体 |
| CRC | 4byte | エラー検出のための情報 |
![[PNGファイル] チャンクの構造](https://runrunsketch.net/wp-content/uploads/2024/02/png_chunk_v3.png)
NovelAIのPNG構造
それでは、いよいよNovelAIのPNGファイルの構造を見てみましょう。
ファイルは次のような構造になっています。
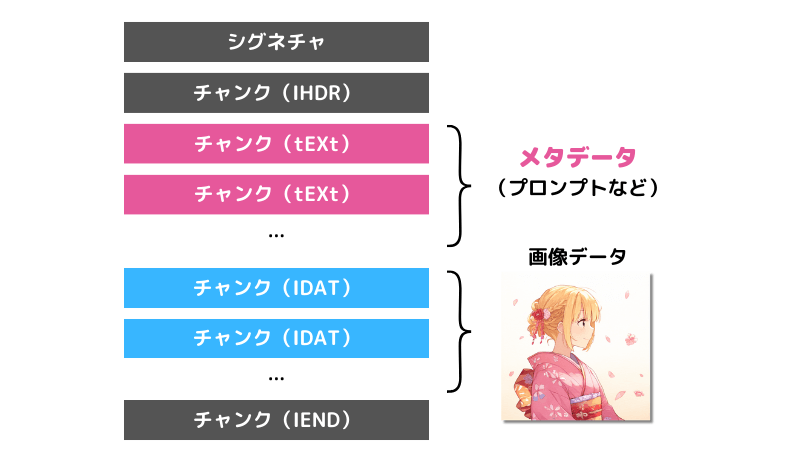
「IDATチャンク」が「画像データ」です。
そして、その前の「tEXtチャンク」または「iTXtチャンク」にプロンプトなどのメタデータが格納されています。
「tEXt」とか「iTXt」ってどんなチャンクなの?
いずれも文字情報を格納するためのチャンクです
tEXtチャンク(テキストデータ)
文字情報が格納されるチャンクです。
![[PNGファイル] tEXtチャンク](https://runrunsketch.net/wp-content/uploads/2024/02/png_chunk_tEXt.png)
Chunk Dataはテキストデータなので基本的にはそのまま読み出せばいいのですが、このテキストデータは情報の種類を示す「キーワード」から始まることがポイントです。
その後、「ヌル文字」で区切られて「テキスト」が続きます。
キーワードには以下のものが事前定義されていますが、ここにないプライベートキーワード(1文字以上、80文字未満)を用いてもよいことになっています。
| キーワード | 意味 |
|---|---|
| Title | 画像の短い(1 行)タイトルまたはキャプション |
| Author | 画像の作成者の名前 |
| Description | 画像の説明 (長い場合もあります) |
| Copyright | 著作権表示 |
| Creation Time | 元画像の作成時間 |
| Software | イメージの作成に使用したソフトウェア |
| Disclaimer | 法的免責事項 |
| Warning | コンテンツの性質に関する警告 |
| Source | イメージの作成に使用されたソースデバイス |
| Comment | その他のコメント |
そして重要なことですが、このテキストに格納できる文字は「Latin-1(ラテン1)」です。
「Latin-1(ラテン1)」は数字・記号・ラテンアルファベットが含まれますが、日本語は含まれません。
つまり、もし日本語でプロンプトを書いていた場合、このtEXtチャンクにその情報を格納できないということです。
あ、でもNovelAIって日本語プロンプトには反応しないよね?
確かにそうなのですが…
NovelAIのプロンプトは日本語に反応しないので英語で書くことが基本です。
ですので、プロンプトに日本語が入っているケースは少ないとは思いますが…可能性はあります。
このように「Latin-1」以外の文字も扱う必要があるときには「iTXtチャンク」を使います。
iTXtチャンク(国際テキストデータ)
iTXtチャンクは意味合いとしてはtEXtチャンクと同じですが、UTF-8の文字を格納することができます。つまり、日本語もOKということです。
ですが、チャンクの構造はtEXtよりもちょっとだけ複雑です。
詳しくはこちらの仕様をご覧ください。
![[PNGファイル] iTXtチャンク](https://runrunsketch.net/wp-content/uploads/2024/02/png_chunk_iTXt.png)
では、この2つのチャンクに着目して、Pythonで実装しながらひとつずつ見ていきましょう。
Pythonでメタデータを読み出してみよう
こちらの記事で解説したコードを再掲します。
pngファイルのメタデータを読み出すコードです。
with open("kimono-girl.png", "rb") as bin:
# 最初の8バイトはPNGであることのシグネチャ(89 50 4E 47 0D 0A 1A 0A)
signature = bin.read(8)
# チャンクの読み出し
while True:
# Length データのサイズ
data_len_b = bin.read(4)
data_len = int.from_bytes(data_len_b, "big")
# Chunk Type チャンクの種類
chunk_type_b = bin.read(4)
chunk_type = chunk_type_b.decode()
print(f"{chunk_type} : {data_len} byte")
# Chunk Data データ
data_b = bin.read(data_len)
if chunk_type == "tEXt":
data = data_b.decode()
print(data.split("\0"))
elif chunk_type == "iTXt":
data = data_b.decode()
print(data.split("\0"))
# CRC
crc_b = bin.read(4)
if chunk_type == "IEND":
break英語プロンプトの画像
では、まずは「英語のプロンプト」で生成したこの画像を使います。
girl, blonde hair, smile, kimono, upper body, profile, watercolor (medium),

whileループを回しながらチャンクをひとつずつ読み出していきます。
NovelAIの場合、「tEXt」または「iTXt」チャンクにメタデータが含まれているので、チャンクタイプがこのいずれかの場合に中身を表示させます。
実行結果がこちらです。
IHDR : 13 byte
tEXt : 24 byte
['Title', 'AI generated image']
tEXt : 146 byte
['Description', 'girl, blonde hair, smile, kimono, upper body, profile, watercolor (medium), , best quality, amazing quality, very aesthetic, absurdres']
tEXt : 16 byte
['Software', 'NovelAI']
tEXt : 35 byte
['Source', 'Stable Diffusion XL C1E1DE52']
tEXt : 32 byte
['Generation time', '4.84797209315002']
tEXt : 1429 byte
['Comment', '{"prompt": "girl, blonde hair, smile, kimono, upper body, profile, watercolor (medium), , best quality, amazing quality, very aesthetic, absurdres", "steps": 28, "height": 640, "width": 640, "scale": 5.0, "uncond_scale": 1.0, "cfg_rescale": 0.0, "seed": 1534611758, "n_samples": 1, "hide_debug_overlay": false, "noise_schedule": "native", "legacy_v3_extend": false, "sampler": "k_euler", "controlnet_strength": 1.0, "controlnet_model": null, "dynamic_thresholding": false, "dynamic_thresholding_percentile": 0.999, "dynamic_thresholding_mimic_scale": 10.0, "sm": false, "sm_dyn": false, "skip_cfg_below_sigma": 0.0, "lora_unet_weights": null, "lora_clip_weights": null, "uc": "nsfw, lowres, {bad}, error, fewer, extra, missing, worst quality, jpeg artifacts, bad quality, watermark, unfinished, displeasing, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract], bad anatomy, bad hands, @_@, mismatched pupils, heart-shaped pupils, glowing eyes, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, huge breasts,worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, missing fingers, bad hands, missing arms, long neck, Humpbacked, shadow, huge breasts, ", "request_type": "PromptGenerateRequest", "signed_hash": "2YV+AgiVe6tOOGt35NslOLkk4JirTLL9zfKsCGR8BK2UfitQB0Spm7lVdh3rLzPkN13ZWKwyYzL4X5tdRzymCg=="}']
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 38355 byte
IEND : 0 byte6つのtEXtチャンクにメタデータが格納されていますね。
1つずつ順番に見てみましょう。
[‘Title’, ‘AI generated image’]
1つめのtEXTチャンクにはAIの生成画像だということが「Title」として格納されています。
[‘Description’, ‘girl, blonde hair, smile, kimono, upper body, profile, watercolor (medium), , best quality, amazing quality, very aesthetic, absurdres’]
「Description」として、「プロンプト」が格納されています。
注目したいのは「品質タグ有効」の設定にしていたため、自動で品質タグ(best quality, amazing quality, very aesthetic, absurdres)が付けられているということです。
[‘Software’, ‘NovelAI’]
NovelAIを使って作られた画像だということが「Software」キーワードとして格納されています。
[‘Source’, ‘Stable Diffusion XL C1E1DE52’]
この「Source」がNovelAIのモデルを表しているようです。正確な仕様は公表されていないようですが、私が実際の生成画像を使って調べた限りでは以下のような対応のようです。
| テキスト | モデル |
|---|---|
| Stable Diffusion XL C1E1DE52 | NAI Diffusion Anime V3 |
| Stable Diffusion F1022D28 | NAI Diffusion Anime V2 |
| Stable Diffusion 3B3287AF | NAI Diffusion Anime V1 (Full) |
| Stable Diffusion F4D50568 | NAI Diffusion Anime V1 (Curated) |
| Stable Diffusion F64BA557 | NAI Diffusion Furry (Beta V1.3) |
[‘Generation time’, ‘4.84797209315002’]
「Generation time」として画像の生成時間が格納されています。
「Generation time」というのはNovelAIオリジナルのキーワードだと思われます
[‘Comment’, ‘{“prompt”: “girl, blonde hair, smile, kimono, upper body, profile, watercolor (medium), , best quality, amazing quality, very aesthetic, absurdres”, “steps”: 28, “height”: 640, “width”: 640, “scale”: 5.0, “uncond_scale”: 1.0, “cfg_rescale”: 0.0, “seed”: 1534611758, “n_samples”: 1, “hide_debug_overlay”: false, “noise_schedule”: “native”, “legacy_v3_extend”: false, “sampler”: “k_euler”, “controlnet_strength”: 1.0, “controlnet_model”: null, “dynamic_thresholding”: false, “dynamic_thresholding_percentile”: 0.999, “dynamic_thresholding_mimic_scale”: 10.0, “sm”: false, “sm_dyn”: false, “skip_cfg_below_sigma”: 0.0, “lora_unet_weights”: null, “lora_clip_weights”: null, “uc”: “nsfw, lowres, {bad}, error, fewer, extra, missing, worst quality, jpeg artifacts, bad quality, watermark, unfinished, displeasing, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract], bad anatomy, bad hands, @_@, mismatched pupils, heart-shaped pupils, glowing eyes, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, huge breasts,worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, missing fingers, bad hands, missing arms, long neck, Humpbacked, shadow, huge breasts, “, “request_type”: “PromptGenerateRequest”, “signed_hash”: “2YV+AgiVe6tOOGt35NslOLkk4JirTLL9zfKsCGR8BK2UfitQB0Spm7lVdh3rLzPkN13ZWKwyYzL4X5tdRzymCg==”}’]
この「Comment」のチャンクには、NovelAIの画像生成パラメータがほぼ盛り込まれているようです。
- プロンプト(prompt)
- 除外したい要素(uc)
- 画像の幅(width)
- 画像の高さ(height)
- シード値(seed)
- ステップ(steps)
- サンプラー(sampler)
- プロンプトを反映する正確度(scale)
- 除外したい要素の強さ(uncond_scale)
- 同時生成数(n_samples)
- i2iの強度(strength)
- i2iのノイズ(noise)
- Txt2ImgかImg2Imgか(request_type)
この画像は英語のプロンプトだったので「iTXt」チャンクの出番はありませんでした。
では次は、日本語プロンプトで生成した画像について見てみましょう💡
日本語プロンプトの画像
こちらの画像を使ってみましょう。以下の日本語プロンプトで生成した画像です。
女性、着物、黒髪、桜

IHDR : 13 byte
tEXt : 24 byte
['Title', 'AI generated image']
iTXt : 104 byte
['Description', '', '', '', '', '女性、着物、黒髪、桜, best quality, amazing quality, very aesthetic, absurdres']
tEXt : 16 byte
['Software', 'NovelAI']
tEXt : 35 byte
['Source', 'Stable Diffusion XL C1E1DE52']
tEXt : 33 byte
['Generation time', '4.244049072731286']
tEXt : 1413 byte
['Comment', '{"prompt": "\\u5973\\u6027\\u3001\\u7740\\u7269\\u3001\\u9ed2\\u9aea\\u3001\\u685c, best quality, amazing quality, very aesthetic, absurdres", "steps": 28, "height": 640, "width": 640, "scale": 5.0, "uncond_scale": 1.0, "cfg_rescale": 0.0, "seed": 1598853643, "n_samples": 1, "hide_debug_overlay": false, "noise_schedule": "native", "legacy_v3_extend": false, "sampler": "k_euler", "controlnet_strength": 1.0, "controlnet_model": null, "dynamic_thresholding": false, "dynamic_thresholding_percentile": 0.999, "dynamic_thresholding_mimic_scale": 10.0, "sm": false, "sm_dyn": false, "skip_cfg_below_sigma": 0.0, "lora_unet_weights": null, "lora_clip_weights": null, "uc": "nsfw, lowres, {bad}, error, fewer, extra, missing, worst quality, jpeg artifacts, bad quality, watermark, unfinished, displeasing, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract], bad anatomy, bad hands, @_@, mismatched pupils, heart-shaped pupils, glowing eyes, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, huge breasts,worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, missing fingers, bad hands, missing arms, long neck, Humpbacked, shadow, huge breasts, ", "request_type": "PromptGenerateRequest", "signed_hash": "cOOKxXryxkWfIuRXOcmpFj5bRLVWuPilpURZYEwMhU1FZyt+QHeTcrlWCsEoApCjEY0OkZybO1+K3zYlrYlpAw=="}']
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 65536 byte
IDAT : 9088 byte
IEND : 0 byte6つのチャンクにメタデータが格納されている点は、英語プロンプトのときと同じです。
差異があるチャンクに注目してみましょう。
[‘Description’, ”, ”, ”, ”, ‘女性、着物、黒髪、桜, best quality, amazing quality, very aesthetic, absurdres’]
2つめのチャンクにはプロンプトが格納されていますが、日本語プロンプトの場合は「tEXt」ではなく「iTXt」チャンクになっています。
[‘Comment’, ‘{“prompt”: “\\u5973\\u6027\\u3001\\u7740\\u7269\\u3001\\u9ed2\\u9aea\\u3001\\u685c, best quality, amazin…(以下省略)]
そして、最後6つめのチャンクです。ここにもプロンプト(日本語)が格納されるのでiTXtチャンクになるのかと思いきや、実際にはtEXtチャンクになっています。そして、日本語プロンプトがそのまま格納されているようです。
tEXtチャンクは「Latin-1」の文字しか使えないので、これは仕様から外れている気がします…
まとめ
NovelAIの生成画像では「プロンプト」などのメタデータが6つのチャンクに格納されています。
| チャンクタイプ | キーワード | 内容 |
|---|---|---|
| tEXt | Title | 固定文字列(AI generated image) |
| tEXtまたはiTXt | Description | プロンプト |
| tEXt | Software | 固定文字列(NovelAI) |
| tEXt | Source | モデル |
| tEXt | Generation | 生成時間 |
| tEXt | Comment | すべてのパラメータ情報 |
Pythonなどでこれらのデータを読み出すことができます。