

Diffusersでimg2imgってできるかな?
StableDiffusionImg2ImgPipelineを使うことで簡単にできます♪

上の記事ではGoogle ColabでWebUIを使わずにStable Diffusionを使う方法を解説しました。
その中では、どのような絵を描きたいかを指示する「テキストから画像を生成」する「text to image(txt2img)」の使い方を紹介しましたが、それだけでなく「画像から画像を生成」する「image to image(img2img)」もGoogle Colabで行うことができます。
この「img2img」は、「画像+テキスト」で絵を生成することができるので、プロンプト(テキスト)だけで指示するよりも、思い描いたイメージに近づけやすいメリットがあります。
img2imgという機能を詳しく知りたい人は、下記の記事も合わせてご覧ください。
>> 【Stable Diffusion】img2imgで写真・ラフ画からイラストを生成するコツを解説
本記事では、WebUIを使わずにStable Diffusionを使うことができる「Diffusers」という仕組みの中でimg2imgを行う方法を解説します。
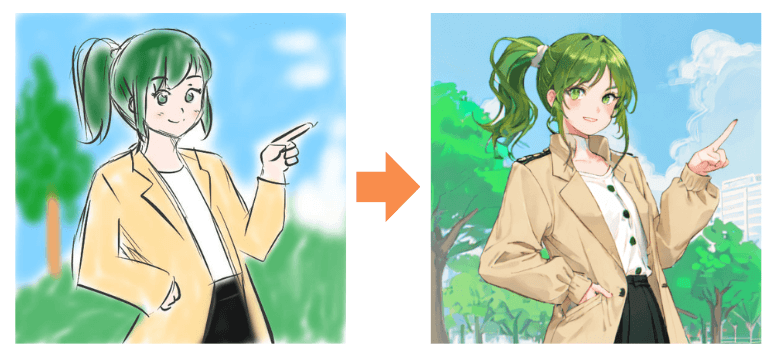
左のような「ラフ画」から、右のようなきれいな絵を生成できるようになります🎨
- Google Colabでimg2imgを使いたい
- 「Diffusers」でimg2imgを行う方法を知りたい
- 完全無料でStable Diffusionのimg2imgをやってみたい
Google Colabでimg2img
それでは最初から順を追って解説していきます。
なお本記事では、下記の記事で解説したプログラムを前提として説明していきます。
「Diffusersって何…?」という人は、まずこちらの記事を一読していただくことをおすすめします。
それではいってみましょう!
元画像の準備
img2imgは、ある画像を参考にして、その画像に近い絵を生成するという機能です。
ですので、まずは元になる画像を準備する必要があります。この元画像には、大きく分けると「写真」と「ラフ画」があります。
ここでは次のような「ラフ画」を下絵として準備しました。

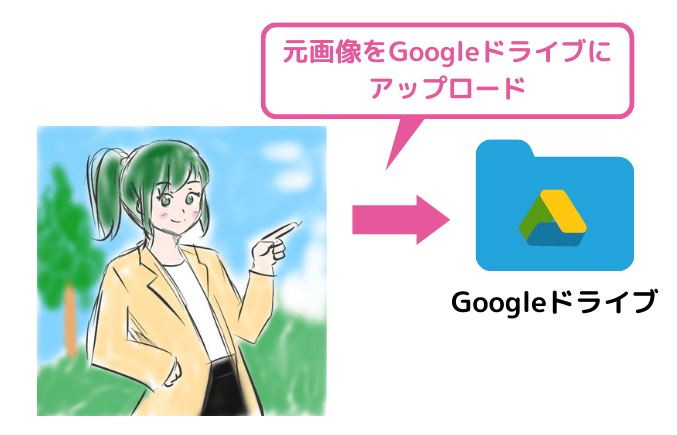
画像のアップロード
準備した画像をGoogle Colabから読み込むために、Googleドライブにアップロードします。
プログラムを動かす
ここからはGoogle Colabでプログラムを書いていきます。
img2imgの実行
まず、必要なライブラリをインストールします。
!pip install --upgrade diffusers accelerate transformers必要なライブラリをインポートして、Diffusersのパイプラインを作ります。
前回の「txt2img」との違いとして、次のポイントに着目です👀
- 「Image」と「StableDiffusionImg2ImgPipeline」をインポート
- StableDiffusionImg2ImgPipelineでパイプラインを作成
ここではモデルとして「MeinaMix V10」を使いますが、model_idを変更すれば好きなモデルで作れます。
モデル選びについては下記の記事も参考にしてみてくださいね
>> 【Stable Diffusion】Diffusersで使えるおすすめモデルを紹介!
from diffusers import StableDiffusionImg2ImgPipeline, DPMSolverMultistepScheduler
import torch
from PIL import Image
# 利用したいAIモデル
model_id = "Meina/MeinaMix_V10"
# パイプラインの作成
pipeline = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None)
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
# GPUを使うように変更
pipeline = pipeline .to("cuda")では、いよいよimg2imgを行っていきます。
まずは、Googleドライブにアップロードした元画像をGoogle Colabからアクセスできるか確認してみます。
画像のパスを調べましょう。
Googleドライブを「マウント」します。
Google Colabの左側メニューの「ファイル」をクリックします。
「ドライブをマウント」をクリックします。
Googleドライブへのアクセスを許可するか聞いてくるので、「Googleドライブに接続」をクリックします。
少し待つと、Googleドライブに接続され、左側メニューのファイルに「drive」というのが表示されます。これがGoogleドライブを表しています。
「drive」の左端の▶を押すと、下の階層を開けます。画像を保存したいフォルダを開きましょう。そのフォルダの右端の「3つの点」ボタンを押して、「パスをコピー」をクリックします。すると、そのフォルダのパスがクリップボードにコピーされます。
画像のパスがわかったら、Google Colabで画像を読み込みます。
新しいセルに下記のコードを入力して実行しましょう。画像のパスを入力 の部分は、先ほど確認したパスに置き換えてください。
コードを実行して、画像が表示されればOK!
init_image = Image.open('/content/drive/MyDrive/StableDiffusion/img2img/i2i_original_sketch.jpg')
# 画像を表示
init_imageでは、この元画像からimg2imgで画像を生成します。新しいセルを追加して、下記のコードを実行しましょう。
どのような画像を生成したいのかをプロンプトで指定するところはtxt2imgと同じです。
赤字のところがimg2imgで重要なパラメータです。
prompt = "girl, light smile, dark green hair, green eyes, ponytail, pointing, index finger raised, beige jacket, blue sky, tree, park "
image = pipeline (prompt=prompt, image=init_image, strength=0.6, num_inference_steps=30).images[0]
# 生成画像を表示
image私の場合は、こんな画像が生成されました。

- image:元画像を指定
- strength:元絵からどれだけ離れた絵を生成するかの度合い
strengthがイマイチわかんないんですけど…
strengthは出来栄えを左右する重要なパラメータです
strengthの調整
img2imgで一番重要なパラメータがstrengthです。これは、元絵からどれくらい離れた絵を生成するかの度合いだと考えてください。
0~1の間で指定することができ、値が小さいほど元絵に近く、値が大きいほど下絵から離れた絵になります。
strengthを小さな値からだんだん大きくしていったのが下の画像です。値が大きくなるにつれて絵がだんだん洗練されていきます。ただし、値を大きくしすぎると、元絵と関係ない絵になってしまいます。

適切なstrengthの値は元絵やプロンプトなどにもよりますので、まず最初にちょうどいいstrengthの値を探ってみましょう。
それから、そのstrengthの値でいい絵が生成されるまで何度かimg2imgを繰り返す、という流れです。
画像の保存
画像の保存についてはtxt2imgと同じです。
import datetime
# 保存したいフォルダのパス
path = "ここに保存したいフォルダのパスを貼り付ける"
# 現在時刻を取得(日本時間)
time = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
time_str = time.strftime("%Y%m%d%H%M%S")
# 保存
image.save(f"{path}/{time_str}.png")以上がGoogle Colabでimg2imgを行う流れです。
意外と簡単♪
まとめ
Google ColabでもDiffusersで「img2img」を簡単に使うことができます。
img2imgでのポイントは「モデル選び」と「strengthの値」です。
また、元絵となる「ラフ画」を描くにはペンタブレットがとても役立ちます。マウスでお絵描きするのは難しいですし、あまり楽しくはないですよね😓
いまは5000円くらいでも品質のいいペンタブレットが手に入ります。よろしければ下記の記事も参考にしてみてくださいね✨

ちなみに私のオススメの1台はこちら!



コメント
丁寧な解説を、ありがとうございます。
最後の画像生成で、
image = pipeline (prompt=prompt, image=init_image, strength=0.6, num_inference_steps=30).images[0]
下記、メモリ不足のエラーが発生しました。
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.53 GiB. GPU 0 has a total capacity of 14.75 GiB of which 871.06 MiB is free. Process 291958 has 13.89 GiB memory in use. Of the allocated memory 13.69 GiB is allocated by PyTorch, and 70.08 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
対処方法がございましたら、お教え願いますでしょうか。
よろしくお願いします。
私の環境でエラーを再現させられなかったため、推測で申し訳ありませんが、以下のような対策が考えられます。
・まず、メニューの「ランタイム」から「ランタイムを接続解除して削除」してもう一度初めからやり直す(=メモリを一旦解放する)
・それでも駄目な場合は、img2imgの元画像のサイズを小さくする
ご回答ありがとうございます。
元画像のサイズを小さくして(1328*968→500*364)、最初からやり直したのですが、残念ながら、またOutOfMemoryErrorになってしまいました。
同時にGPUの上限に達したようですので、解除されてから、また挑戦してみたいと思います。
ありがとうございました。
あまりお役に立てず申し訳ありません…。私の方でも解決策が見つかればまた情報展開させていただきます。
お手数をお掛けして申し訳ございません。
元画像として、るんさんの上記ラフ画を使わせていただいたところ、無事、AI画像を生成することができました。
元画像の仕様などありましたら、教えていただけると幸いです。
私のラフ画だとうまくいくのは不思議ですね。CLIP STUDIO PAINTで描いたラフ画でサイズは535×535のjpeg形式です。
その後、私も試してみたのですが、白黒画像だと生成に失敗するケースがありました。
ファイルをopenする以下の箇所のコードを以下のように変更してみると上手くいく可能性があります。(私の場合はそれで改善しました)
【変更前】
init_image = Image.open(‘/content/drive/MyDrive/StableDiffusion/img2img/i2i_original_sketch.jpg’)
【変更後】
init_image = Image.open(‘/content/drive/MyDrive/StableDiffusion/img2img/i2i_original_sketch.jpg’).convert(“RGB”)